Concept Frequency-Inverse Concept Document Frquency: Analyzing Concepts in Text
x
* [Intro](#Intro)* [Word Embeddings and Semantic Similarity](#Word-Embeddings-and-Semantic-Similarity)* [Calculating CFIDF](#Calculating-CFIDF)* [Visualizing CFIDF](#Visualizing-CFIDF)* [What it's not](#What-it's-not)* [What's Next](#What's-Next)# IntroIntro¶
xxxxxxxxxx<b>C</b>oncept <b>F</b>requency-<b>I</b>nverse Concept <b>D</b>ocument <b>F</b>requency (or CFIDF) is a measure I've created to explore text data and it works surprisingly well for exploring and visualizing text data. As opposed to its statistical parent TF-IDF, it isn't based strictly on word counts, but on *entire concepts*, assuming that you're word embedding layer is trained appropriately. First, it may help to explain what TF-IDF accomplishes. Most of NLP is trying to figure out what a body of text is about. TF-IDF is crucial to answering this question as it calculates how unique a word is to a document compared to other documents in the corpus. If you can measure how important a set of words is to a document, then you're one step closer to answering what the document is about. One problem here is the issue of synonyms, commonly misspelled words, and even conceptually similar words or phrases. These issues tend to dilute the impact a word has on a document. This is where CFIDF comes in. Concept Frequency-Inverse Concept Document Frequency (or CFIDF) is a measure I've created to explore text data and it works surprisingly well for exploring and visualizing text data. As opposed to its statistical parent TF-IDF, it isn't based strictly on word counts, but on entire concepts, assuming that you're word embedding layer is trained appropriately. First, it may help to explain what TF-IDF accomplishes.
Most of NLP is trying to figure out what a body of text is about. TF-IDF is crucial to answering this question as it calculates how unique a word is to a document compared to other documents in the corpus. If you can measure how important a set of words is to a document, then you're one step closer to answering what the document is about. One problem here is the issue of synonyms, commonly misspelled words, and even conceptually similar words or phrases. These issues tend to dilute the impact a word has on a document. This is where CFIDF comes in.
xxxxxxxxxx# Word Embeddings and Semantic SimilarityWord Embeddings and Semantic Similarity¶
xxxxxxxxxxWord2Vec, which is the word embedding algorithm I use here (but you can use any word embedding algorithm), produces measures of semantic similarity. This allows us to determine if two words are semantically similar (or conceptually similar), regardless if they are synonyms, commonly misspelled words, or different parts of speech entirely. Thus, with CFIDF, we can calculate how *frequent a concept* shows up in a document compared to how frequent it shows up in other documents in a corpus. Word2Vec, which is the word embedding algorithm I use here (but you can use any word embedding algorithm), produces measures of semantic similarity. This allows us to determine if two words are semantically similar (or conceptually similar), regardless if they are synonyms, commonly misspelled words, or different parts of speech entirely. Thus, with CFIDF, we can calculate how frequent a concept shows up in a document compared to how frequent it shows up in other documents in a corpus.
# Calculating CFIDFCalculating CFIDF¶
xxxxxxxxxxCalculating CFIDF is pretty straight forward and almost exactly like TF-IDF but instead of using term frequency you use *concept frequency*. To do this, you establish a user-defined similarity threshold on your similarity queries to your word embeddings. If a word in the document is above this threshold then we count that as being conceptually similar and thus increasing concept frequency (it may help to set thresholds on each concept/target word individually). Calculating CFIDF is pretty straight forward and almost exactly like TF-IDF but instead of using term frequency you use concept frequency. To do this, you establish a user-defined similarity threshold on your similarity queries to your word embeddings. If a word in the document is above this threshold then we count that as being conceptually similar and thus increasing concept frequency (it may help to set thresholds on each concept/target word individually).
xxxxxxxxxxOne may notice that I'm computing concept frequency by dividing the number of times a concept appears by the total number of *terms* in the document. Since we can't easily detect the number of concepts present this will have to do as a way to account for document length.One may notice that I'm computing concept frequency by dividing the number of times a concept appears by the total number of terms in the document. Since we can't easily detect the number of concepts present this will have to do as a way to account for document length.
$$cf(c,d) = {\displaystyle f_{c,d}{\Bigg /}{\sum _{t'\in d}{f_{t',d}}}} $$
xxxxxxxxxxI calculate inverse concept document frequency by using the following formula:$$ \mathrm{idf}(c, D) = \log \frac{N}{1+|\{d \in D: c \in d\}|}$$I calculate inverse concept document frequency by using the following formula:
With N being the total number of documents in the corpus or $$ N = {|D|} $$The denominator:$$1+|\{d \in D: c \in d\}|$$ is the number of documents where the concept c appears, and I add the constant 1 to avoid division by zero.With N being the total number of documents in the corpus or The denominator:
is the number of documents where the concept c appears, and I add the constant 1 to avoid division by zero.
# Visualizing CFIDFVisualizing CFIDF¶
xxxxxxxxxxCFIDF is great for exploring text that you are conceptually familiar with or where you roughly know what concepts are mentioned. It's also great for comparing text. Take the following ternary plot, for example, where we look at song lyrics. (It should be obvious <a href="https://tmthyjames.github.io/2018/january/Cypher/" target="_blank">now</a> <a href="https://tmthyjames.github.io/2018/january/Analyzing-Rap-Lyrics-Using-Word-Vectors/" target="_blank">that</a> <a href="https://tmthyjames.github.io/2018/february/Predicting-Musical-Genres/" target="_blank">I</a> <a href="https://tmthyjames.github.io/2018/june/Expose-Word2vec-Model-with-a-RESTful-API-Using-Only-a-Jupyter-Notebook/" target="_blank">love</a> <a href="https://tmthyjames.github.io/2018/august/Using-Bigram-Paragraph-Vectors/" target="_blank">rap</a> <a href="https://www.youtube.com/watch?v=L4Nd7lZgp4o" target="_blank">music</a>).We have specified three concepts to which we want to map artists to a certain degree. If an artist lands in the middle, then they likely write about all three concepts equally. If they land where Jackie Wilson does in this example (left edge), then that means they write about `family` and `money` equally but shy away from `politics`. This exmaple shows that metal and punk artists tend to write about `politics` more so than `family` or `money`. And rap artists tend to rap about `money` over `family` and `politics` in general. Anecdotally, we can confirm this by looking at metal and punk artists like Fear Factory and Rage Against the Machine, two artists known to politic. Also notice the rapper Immortal Technique's position, who is known to engage in political lyricism. It should be no surprise that country artists tend to lean towards `family` concepts.CFIDF is great for exploring text that you are conceptually familiar with or where you roughly know what concepts are mentioned. It's also great for comparing text. Take the following ternary plot, for example, where we look at song lyrics. (It should be obvious now that I love rap music).
We have specified three concepts to which we want to map artists to a certain degree. If an artist lands in the middle, then they likely write about all three concepts equally. If they land where Jackie Wilson does in this example (left edge), then that means they write about family and money equally but shy away from politics. This exmaple shows that metal and punk artists tend to write about politics more so than family or money. And rap artists tend to rap about money over family and politics in general. Anecdotally, we can confirm this by looking at metal and punk artists like Fear Factory and Rage Against the Machine, two artists known to politic. Also notice the rapper Immortal Technique's position, who is known to engage in political lyricism. It should be no surprise that country artists tend to lean towards family concepts.
<img src="29.png"></img>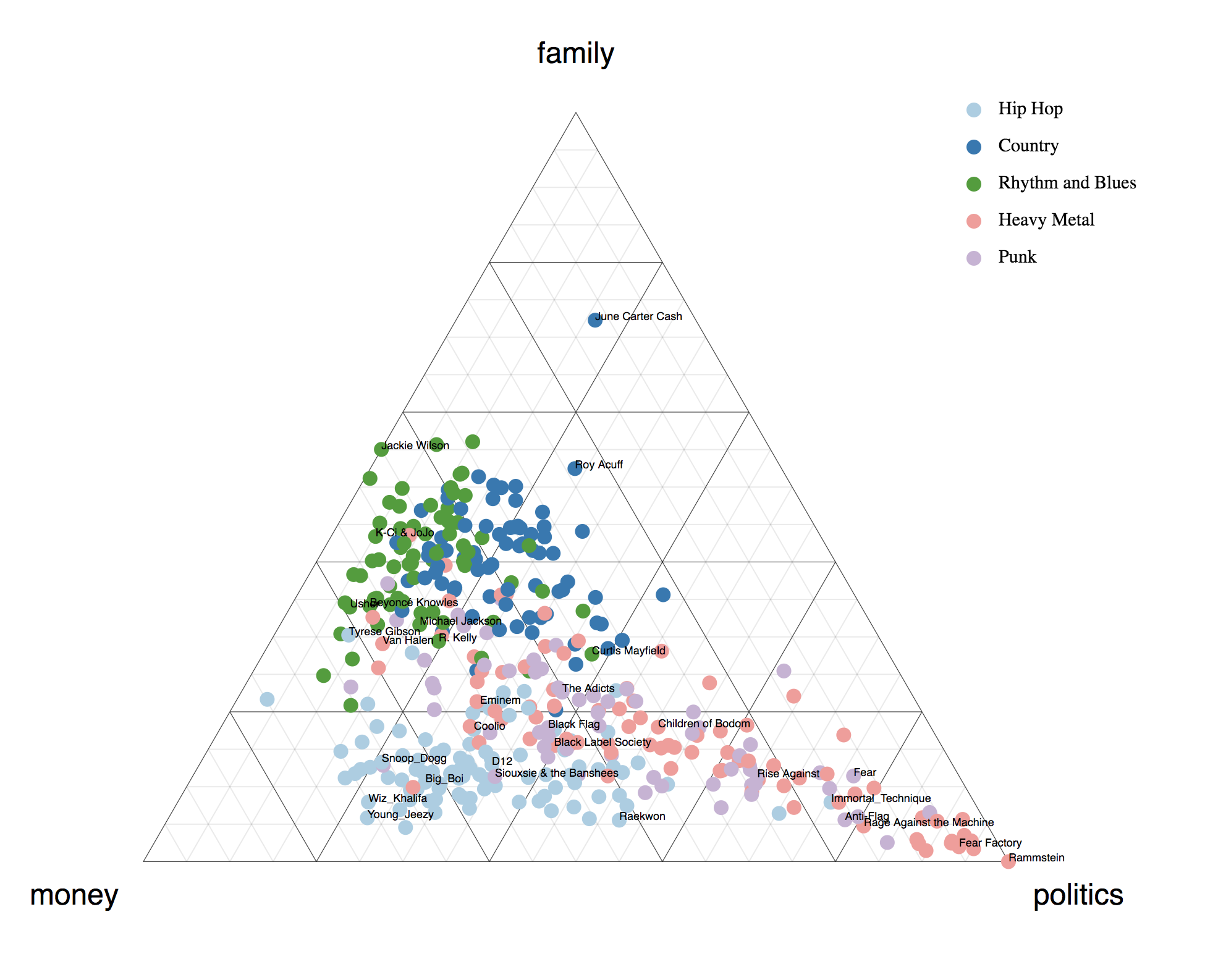
xxxxxxxxxxWhen the concepts of interest are `politics`, `drugs`, and `sex`, we see pretty definite segmentation: rap leans towards drugs, heavy metal leans toward politics, and R&B dominates the sex category, as one would expect, right?When the concepts of interest are politics, drugs, and sex, we see pretty definite segmentation: rap leans towards drugs, heavy metal leans toward politics, and R&B dominates the sex category, as one would expect, right?
<img src="19.png"></img>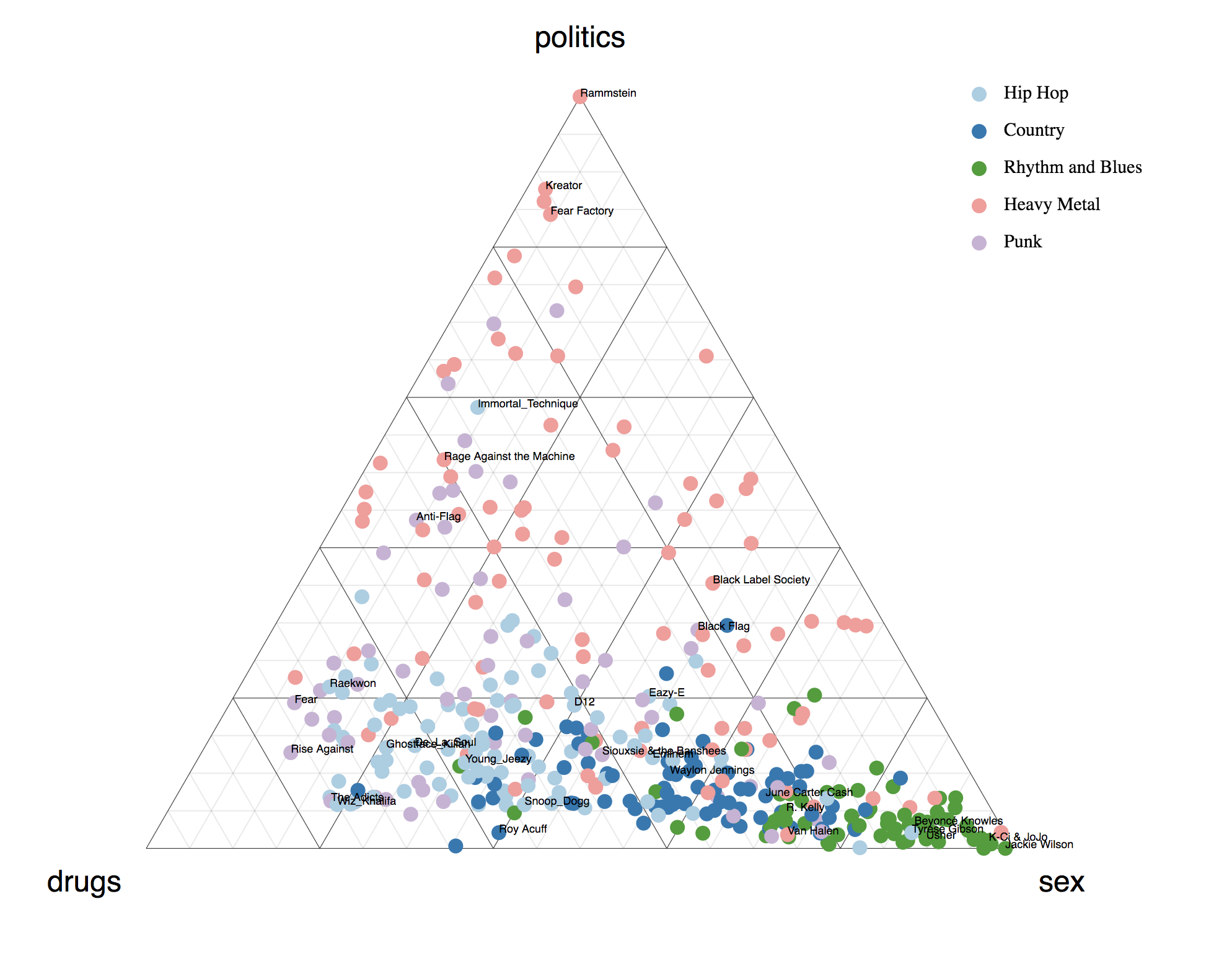
xxxxxxxxxxHere's all the CFIDF scores by artist and genre:Here's all the CFIDF scores by artist and genre:
import pandas as pdcfidf = pd.read_csv('cf-idf.csv')cfidf# What it's notWhat it's not¶
xxxxxxxxxx• Although possible, CFIDF is not meant to be used as a predictive algorithm. You're much better off using your word embeddings as features instead of the learned features *produced* by your word embeddings.• CFIDF is not designed for topic modeling as it doesn't "discover" topics. CFIDF assumes you've specified your topics (or concepts) of interest a priori. It may be helpful for a priori topic/concept analysis though. On the other hand, it works great for texts where you have a set of concepts you're interested in analyzing, where you may have a lot of overlapping language (money vs cash), and/or where you know (roughly) what concepts exist in the text already. • Although possible, CFIDF is not meant to be used as a predictive algorithm. You're much better off using your word embeddings as features instead of the learned features produced by your word embeddings.
• CFIDF is not designed for topic modeling as it doesn't "discover" topics. CFIDF assumes you've specified your topics (or concepts) of interest a priori. It may be helpful for a priori topic/concept analysis though.
On the other hand, it works great for texts where you have a set of concepts you're interested in analyzing, where you may have a lot of overlapping language (money vs cash), and/or where you know (roughly) what concepts exist in the text already.
# What's NextWhat's Next¶
xxxxxxxxxxThis is a good start for determining which *concepts*, as opposed to terms, are unique to a document. But it's not perfect. One flaw with this specific example is my use of <a href="https://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf">Word2Vec</a> for training word embeddings that produce the CFIDF scores. The problem is that Word2Vec produces a single vector representation for each word, regardless of the context of the word. This poses two problems. One, it doesn't take into account the complex characteristics of word use (word-sense ambiguity); two, it doesn't model <a href="https://en.wikipedia.org/wiki/Polysemy">polysemic</a> words whose meanings vary across linguistic contexts. JR Firth, pioneer of distributional semantics, said>The complete meaning of a word is always contextual, and no study of meaning apart from context can be taken seriously.Although Word2Vec takes context words into account, it assigns one vector representation to each word, regardless of how the word is used. So although it does a great job of learning semantic similarity (*hot-cold*, *computer-tv*, *hand-foot*), it isn't as adept at learning semantic relatedness (*hot-sun*, *computer-database*, *hand-ring*) because of its one-embedding-per-word architecture.This distinction is important. Take the example *cup-bottle* vs *necklace-neck*. The first pair of words are semantically *similar*. That is, they are roughly interchangeable and similar in function. However, the second pair of words are merely semantically *related*—they share a common theme but aren't interchangeable nor functionally similar. If, for example, I'm interested in finding conceptual similarities for `partying`, then *cup* and *bottle* would likely both make the cut. But If I'm interested in finding concepts similar to `money` then although *necklace* may contribute, *neck* likely will not because it's not semantically similar. Choosing a word-embedding architecture that supports multiple vector representations per word depending on context could likely improve the results of CFIDF.Asr et al., in <a href="https://aclweb.org/anthology/N18-1062">Querying Word Embeddings for Similarity and Relatedness</a> said:> It may be unrealistic to expect a single vector representation to account for qualitatively distinct similarity and relatedness data.They went on to empirically show that although word embeddings are best for finding semantic similarities, contexualized word embeddings are better indicators of semantic relatedness. Much work has been done to differentiate semantic relatedness and semantic similarity and to solve the problems of word-sense ambiguity and polysemy modeling (see the <a href="http://papers.nips.cc/paper/7209-learned-in-translation-contextualized-word-vectors.pdf">CoVe paper</a>, and the <a href="https://arxiv.org/pdf/1802.05365.pdf">ELMo paper</a>). ELMo, as opposed to Word2Vec, uses a language model (predicting the next word in a sequence of words; more on language models <a href="https://machinelearningmastery.com/statistical-language-modeling-and-neural-language-models/">here</a>) to solve our two problems: word context (word-sense disambiguation) and linguistic context (polysemy modeling). It does this by producing an embedding for a word *based on the context in which it appears*, therefore producing a slightly different embedding for each word's occurences, thus better disambiguating each word and providing more context to our text data!Therefore, for better CFIDF performance, try <a href="https://arxiv.org/pdf/1802.05365.pdf"> deep *contexualized* word representations</a> (my next step is to use ELMo embeddings to produce CFIDF scores).This is a good start for determining which concepts, as opposed to terms, are unique to a document. But it's not perfect. One flaw with this specific example is my use of Word2Vec for training word embeddings that produce the CFIDF scores. The problem is that Word2Vec produces a single vector representation for each word, regardless of the context of the word. This poses two problems. One, it doesn't take into account the complex characteristics of word use (word-sense ambiguity); two, it doesn't model polysemic words whose meanings vary across linguistic contexts. JR Firth, pioneer of distributional semantics, said
The complete meaning of a word is always contextual, and no study of meaning apart from context can be taken seriously.
Although Word2Vec takes context words into account, it assigns one vector representation to each word, regardless of how the word is used. So although it does a great job of learning semantic similarity (hot-cold, computer-tv, hand-foot), it isn't as adept at learning semantic relatedness (hot-sun, computer-database, hand-ring) because of its one-embedding-per-word architecture.
This distinction is important. Take the example cup-bottle vs necklace-neck. The first pair of words are semantically similar. That is, they are roughly interchangeable and similar in function. However, the second pair of words are merely semantically related—they share a common theme but aren't interchangeable nor functionally similar. If, for example, I'm interested in finding conceptual similarities for partying, then cup and bottle would likely both make the cut. But If I'm interested in finding concepts similar to money then although necklace may contribute, neck likely will not because it's not semantically similar. Choosing a word-embedding architecture that supports multiple vector representations per word depending on context could likely improve the results of CFIDF.
Asr et al., in Querying Word Embeddings for Similarity and Relatedness said:
It may be unrealistic to expect a single vector representation to account for qualitatively distinct similarity and relatedness data.
They went on to empirically show that although word embeddings are best for finding semantic similarities, contexualized word embeddings are better indicators of semantic relatedness.
Much work has been done to differentiate semantic relatedness and semantic similarity and to solve the problems of word-sense ambiguity and polysemy modeling (see the CoVe paper, and the ELMo paper).
ELMo, as opposed to Word2Vec, uses a language model (predicting the next word in a sequence of words; more on language models here) to solve our two problems: word context (word-sense disambiguation) and linguistic context (polysemy modeling). It does this by producing an embedding for a word based on the context in which it appears, therefore producing a slightly different embedding for each word's occurences, thus better disambiguating each word and providing more context to our text data!
Therefore, for better CFIDF performance, try deep contexualized word representations (my next step is to use ELMo embeddings to produce CFIDF scores).
xxxxxxxxxxHT to <a href="https://bl.ocks.org/tomgp">Tom Pearson</a> and <a href="http://bl.ocks.org/tomgp/7674234">this</a> block for the <a href="https://d3js.org/">d3.js</a> inspiration.HT to Tom Pearson and this block for the d3.js inspiration.